Japanese Text on Computers
日本語の不思議
A tour of the writing system, the fonts, and the engineering problems they cause.
One sentence, three scripts
私はコーヒーを飲む。(I drink coffee.)
- 私, 飲: Kanji (Chinese-origin)
- は, を, む: Hiragana (grammar / verb endings)
- コーヒー: Katakana (loanword from English "coffee")
The three writing systems
Same sounds, two scripts
Columns = vowels, rows = consonants. Each cell has the hiragana and its katakana twin (same sound, different glyph).
| a | i | u | e | o | |
|---|---|---|---|---|---|
| · | あア | いイ | うウ | えエ | おオ |
| k | かカ | きキ | くク | けケ | こコ |
| s | さサ | しシ | すス | せセ | そソ |
| t | たタ | ちチ | つツ | てテ | とト |
| n | なナ | にニ | ぬヌ | ねネ | のノ |
| h | はハ | ひヒ | ふフ | へヘ | ほホ |
| m | まマ | みミ | むム | めメ | もモ |
| y | やヤ | · | ゆユ | · | よヨ |
| r | らラ | りリ | るル | れレ | ろロ |
| w | わワ | · | · | · | をヲ |
| n | んン | · | · | · | · |
Small kana: yōon
Add a small ゃ ゅ ょ after any i-column kana → combined syllable.
| + ゃ | + ゅ | + ょ | |
|---|---|---|---|
| き ki | きゃ kya | きゅ kyu | きょ kyo |
| し shi | しゃ sha | しゅ shu | しょ sho |
| ち chi | ちゃ cha | ちゅ chu | ちょ cho |
| り ri | りゃ rya | りゅ ryu | りょ ryo |
しゃしん (photo), きょう (today), りょこう (trip)
Small kana: sokuon
A small っ (like つ, shrunk) doubles the next consonant.
| Without | With small っ | |
|---|---|---|
| おと oto | おっと otto | sound → husband |
| かこ kako | かっこ kakko | past → parentheses |
| まて mate | まって matte | wait (root) → "wait!" |
In speech: a brief glottal stop. In writing: a tiny っ that changes the word entirely.
Voicing marks: dakuten ゛
Add ゛ to flip a consonant from unvoiced to voiced. Applies across whole rows.
| Unvoiced | + ゛ → voiced | Sound shift | |
|---|---|---|---|
| k-row | か ka | が ga | k → g |
| s-row | さ sa | ざ za | s → z |
| t-row | た ta | だ da | t → d |
| h-row | は ha | ば ba | h → b |
Rule extends across all 5 vowels: か き く け こ → が ぎ ぐ げ ご
H-row's special twin: handakuten ゜
A small ゜ circle (only valid on the h-row) gives the unvoiced plosive p.
Only row with three forms. The h-row is phonetically unstable, so it picked up an extra diacritic over the centuries.
How many glyphs?
Log scale: every order of magnitude is the same width on screen. Linear scale: Latin and Jōyō almost vanish next to the full CJK set.
What does this cost on the web?
woff2, same font family (Noto Sans / Inter) where possible.
Subsetting to the rescue
@font-face {
font-family: "Noto Sans JP";
src: url("noto-jp-subset-hiragana.woff2") format("woff2");
unicode-range: U+3040-309F; /* hiragana block only */
}
Google Fonts splits Noto Sans JP into ~120 subsets.
The browser downloads just the chunks that contain characters on the page.
Or: skip kanji entirely
Pokémon FireRed (Game Boy Advance, 2004). All UI in hiragana & katakana, no kanji.
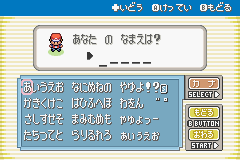
"あなたの なまえは?". Note the space between あなたの and なまえは, and the entire keyboard is just kana.
What in-game dialogue looked like
しんじん トレーナーの きみは
ポケモンと ぼうけんを はじめる!
→ with kanji: 新人トレーナーの 君は ポケモンと 冒険を 始める!
"You, a rookie trainer, set off on an adventure with Pokémon!"
Why drop kanji?
Each kanji is a 16×16 bitmap → 32 bytes.
A full Jōyō set: 2,136 × 32 ≈
68 KB of pure glyph data.
For comparison: Pokémon Red & Blue
(Game Boy, 1996) shipped
the entire game in
1 MB.
156 Pokémon, all sprites, all maps, all
music, all code.
A full kanji set would have been ~7% of that cartridge, just for the letters.
Easier: ship the 92 kana glyphs, skip kanji altogether.
But then: readability tanks
こうこうにいきます
Could be: 高校 (high school) / 孝行 (filial piety) / 後攻 (going second) / 高々 (at most)…
Solution Pokémon adopted: add spaces between phrases, a thing Japanese normally doesn't have.
Hardware caught up
| 2004 | Pokémon FireRed (GBA): kana only |
| 2006 | Diamond/Pearl (DS): kanji as an option |
| 2013 | X/Y (3DS): kanji on by default |
The same problem the web solved with subsetting, games solved by waiting for ROM to get cheap.
No spaces. Anywhere.
おすしを食べました
Where does each word start?
お (honorific) + すし (sushi) + を (object marker) + 食べ (eat, verb stem) + ました (polite past)
Need a dictionary and grammar rules to do this.
Compounds make it worse
電車 = 電 (electricity) + 車 (vehicle) = train
図書館 = 図 + 書 + 館 = library
A naïve Ctrl+F for
車 finds
電車,
自動車,
車道,
自転車…
you almost never want that.
…but compounds can be poetry
Each character carries meaning. Stack them and you get a tiny picture.
Counters: count by shape
Japanese has no grammatical plural. But it has ~50 counter words that change based on the shape of the thing being counted.
| Japanese | Counter | Used for | |
|---|---|---|---|
| 2 cars | 車を2台 | 台 dai | machines |
| 2 cats | 猫を2匹 | 匹 hiki | small animals |
| 2 horses | 馬を2頭 | 頭 tō | large animals |
| 2 books | 本を2冊 | 冊 satsu | bound things |
| 2 sheets of paper | 紙を2枚 | 枚 mai | flat thin things |
| 2 pencils | 鉛筆を2本 | 本 hon | long cylindrical things |
| 2 rabbits | うさぎを2羽 | 羽 wa | birds… and rabbits 🐇 |
So localization has to know which counter goes with which noun. (We'll come back to this.)
What i18n libraries can't do for you
English needs plural forms. Japanese needs something CLDR doesn't ship.
new Intl.PluralRules('en').select(1) // "one"
new Intl.PluralRules('en').select(2) // "other"
new Intl.PluralRules('ja').select(1) // "other"
new Intl.PluralRules('ja').select(2) // "other"
Japanese has exactly one plural category. The library has nothing to do.
The real problem isn't grammar, it's lexical:
猫 → 匹, 本 → 冊, 鉛筆 → 本… (per-noun, not per-language; no standard library knows this)
Plus the phonetic mutation: the number itself changes the counter's reading.
What apps actually do: hard-code per noun, or punt to 個 (ko), the generic "thing" counter.
So how do learners read?
A browser extension that tokenizes + dictionary-looks-up under your cursor.
Yomitan
Yomitan in one sentence
Hover any Japanese text →
it segments words, deinflects them, and
shows the dictionary entry.
-
食べました→食べる(deinflected to dictionary form) - Shows readings, meanings, frequency, pitch accent
- Bring your own dictionaries
Bring your own dictionaries
Yomitan ships empty. You import whichever dictionary files suit how you read.
Longest match wins
Hover anywhere. Yomitan reads forward from your cursor and picks the longest entry it can find.
図書館にいきます
So hovering 図 in this sentence pops up library, not "diagram", even though both are valid.
Live demo
Open the link, hover any sentence.
今日は寿司を食べました。
And how do you type all this?
Reading was one side. The other side is input: the IME (Input Method Editor). Built into every desktop, phone, and browser.
Three layers of conversion between the keyboard and what lands in the document.
Picking from candidates
Press space again. The IME shows every kanji string the kana could possibly spell.
- 日本語 Japanese language ★ default
- 二本後 "after 2 cylindrical things"
- 2本後 mixed numeral + counter
- にほんご leave as hiragana
- ニホンゴ force katakana
Arrow keys or number keys to pick. The IME learns your preferences and reorders next time.
How many kanji do you actually need?
Approx. cumulative coverage of running newspaper text by the top-N most frequent kanji.
The official list: Jōyō kanji
常用漢字: "regular-use kanji"
(since the 2010 revision)
- Defined by the government. Schools, newspapers, and official documents commit to staying within this set.
- Anything outside → write in kana, or add furigana.
- So "~2,000 kanji" on the previous chart isn't arbitrary. It's the curriculum.
Furigana: kanji with training wheels
Tiny kana printed above (or beside) kanji to show how to read them.
私は学校に行きます。
Where you see it: children's books, manga, learners' material, place & person names with rare readings.
HTML ships with <ruby>
The web has a native element for exactly this, for over 20 years, in every browser.
<ruby>
漢字
<rp>(</rp><rt>かんじ</rt><rp>)</rp>
</ruby>
Renders as: 漢字
-
<rt>: the small "ruby text" annotation -
<rp>: fallback parentheses for browsers without ruby support (modern browsers ignore them)
Also handy for: chemical formulas (H2O), abbreviation expansions, screen-reader-friendly pronunciation hints.
Stroke order matters
語
(language)
0 / 14 strokes
Stroke data: KanjiVG (CC BY-SA 3.0)
Reading text from images
OCR: Optical Character Recognition. Pixels in, text out.
You use it constantly:
- Google Lens, Apple Live Text
- Searchable PDFs, document scanners
- Receipts, business cards, license plates
- Translating signs and menus on the go
For English: largely solved. For Japanese: still rough.
OCR: harder than it looks
26 letters vs ~6,000 glyphs
Some kanji differ by a single stroke.
Spot the difference
| Pair | Meaning | |
|---|---|---|
| 1 | 末 / 未 | end / not yet |
| 2 | 土 / 士 | earth / samurai |
| 3 | 日 / 曰 | sun / say |
| 4 | 人 / 入 | person / enter |
At low resolution? Good luck.
And then there's manga
きょうは
いい
てんき
だね
漢字に振り仮名
→ specialised tools like
mokuro,
manga-ocr.
One last thing: emoji
1999. Shigetaka Kurita at NTT DoCoMo designs 176 12×12 pixel icons so pager messages can express more on tiny screens.
Same constraint we've been tracking all talk: tiny budget, want to say more. The Japanese answer: ship pictures as characters.
2008: iPhone picks them up. 2010: Unicode adopts them. Today: ~3,800 in the standard, and you've sent thousands.
Thank you!
My name is Truls
Slides on github:
github.com/trulshj/presentation
Tools mentioned: Yomitan, KanjiVG, mokuro, manga-ocr, Noto Sans JP